
How to Create a Custom Airflow Operator
At Quaker Analytics, we use DAGs in Apache Airflow and their underlying Operators to run a multitude of data pipeline procedures. They are excellent tools to manage and preprocess datasets, access big query, update tables & records and monitor for incoming files.
When we make custom airflow operators we are able to construct with the parameters we need for use in data processing and ultimately our models. This customization ability allows for changing default parameters to suit our specific data warehousing and processing needs.
In Apache Airflow, a DAG or Directed Acyclic Graph, is a grouping of different tasks that you want to have completed. DAGs are defined in a Python script, where each task of your workflow is represented in code. They can be organized in a specified order, with or without dependencies, timeouts and scheduled runs.
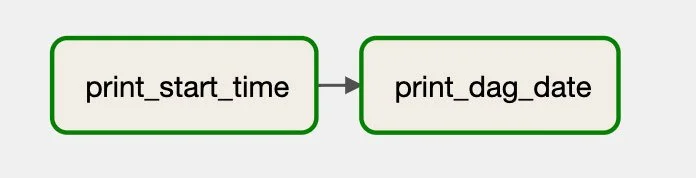
• Sample DAG with 2 tasks to run:
1. print_start_time
2. print_dag_date
If DAGs are composed of tasks, the code building blocks of DAGs are Operators. Operators either perform the task or tell another system to perform the task and their code is where you define the actual work that is to be done. The code below represents the visual workflow above with 2 tasks being run in succession.

Figure 2

Figure 3
The code snippet above defines the first task, print_start_time, which creates the variable that stores the task instance.
BashOperator(): specifies that BashOperator will be used to execute the task.
task_id=‘print_start_time’: unique identifier for the task.
bash_command=‘echo “DAG start time: {{ dag_run.start_date }} ...”’:
The command to execute the following:
‘echo: Bash command for printing output to the console.
{{ dag_run.start_date }}: template variable that gets replaced with the actual start date + time when the DAG is run.
“DAG start time: ”, “ ...”: text to print around DAG template variable specified by brackets i.e. {{ ds }}.
If the task ‘print_start_time’ was executed within the DAG, here is an example output you might get in the Logs for task: “print_start_time”:

Figure 4
In Airflow you can use the default Operator classes that are built-in for most tasks. However, sometimes you need to change the default parameters to meet your specific needs. This can be done by creating a custom Operator which extends or redefines the BaseOperator(), the base class for all Airflow Operators.
In our case we wanted to run an Airflow DAG that contained a task to execute a sql query that returns a log output. We encountered a few different errors with different ideas and operators until we created a custom operator to meet our specific needs. We’ll explain some issues we had first before highlighting our solution of creating a custom Operator class.
SqlSensor() - This DAG prints the start time of the DAG run and then uses an SQL sensor to monitor a condition in a BigQuery table, checking if the latest entry has an ‘action’ like ‘Do Nothing’. The sensor runs periodically, poking the condition until it is met or a timeout occurs. We had issues with this sensor connecting and running the sql code.
conn_id=: the Airflow connection ID to use when executing the SQL query.
sql=: where the SQL query is specified. It checks the latest entry in the table report_1_log. If the ‘action’ field is like ‘Do Nothing’, the condition is considered met.
poke_interval=: sets the interval (in seconds) at which the sensor task should check the condition.
timeout=: sets the maximum amount of time (in seconds) that the sensor task will wait for the condition to be met before timing out.
mode=: specifies that the sensor will repeatedly poke (check) the condition until it is met or the timeout is reached.
Our code failed multiple edits for this reason:
FAILED:
Task failed with exception. airflow.exceptions.AirflowException: Need to specify ‘location’ to use BigQueryHook.get_records()

Figure 5
GCSUploadSessionCompleteSensor() - We then switched the process to check for a file in a folder that would be created if the same process above was successful. This task creates a sensor that monitors a GCS upload session, waiting for a specific file to be uploaded before allowing the DAG to proceed. Sensors are commonly used to ensure data availability before downstream tasks begin processing. We encountered issues with this sensor, which returns True if the inactivity period has passed with no increase in the number of objects in the bucket. The min_objects feature was set to 1, but it kept succeeding while the test_prefix pointed at the empty folder before the file was uploaded.
SUCCESS:
Sensor found 1 objects at client_name/project_name/file_folder/file_1. Waited at least 120 seconds , with no new objects dropped.
a. Variable “inactivity_period=2*60” is the 120 seconds
b. Variable “min_objects=1” succeeded with no files
c. The folder “test_prefix” was empty the entire run

Figure 6
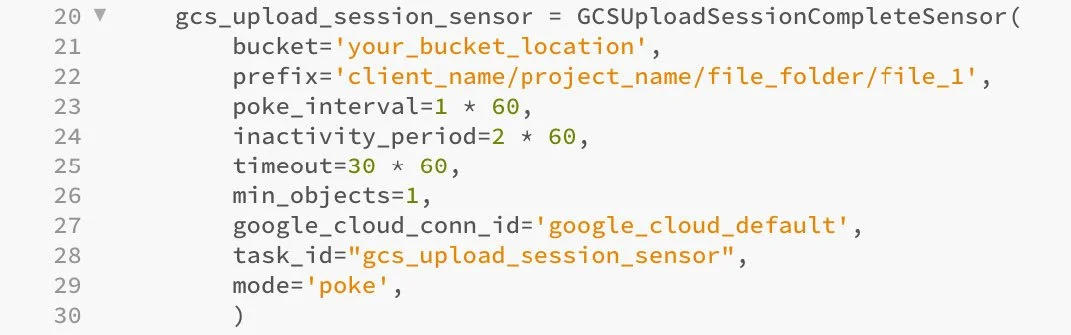
Figure 7
This code defines the second task, ‘gcs_upload_session_sensor’. The task creates a sensor that monitors a GCS upload session, waiting for a specific file to be uploaded before allowing the DAG to proceed. Sensors can be used to ensure data availability before downstream tasks begin processing.
gcs_upload_session_sensor: creates the variable storing the task instance.
GCSUploadSessionCompleteSensor(: specifies that the task will use a GCSUploadSessionSensor to look for a file called ‘file_1’.
bucket=: sets the name of the GCS bucket where the file will be uploaded.
prefix=: specifies the path from the bucket to monitor for the uploaded file.
poke_interval=: sets the interval (in seconds) after which the sensor will consider the upload session complete, even if the file is not yet present.
timeout=: sets a maximum time limit (in seconds) for the sensor to wait for the file. If the timeout is reached, the sensor will fail.
min_objects=: indicates that the sensor expects at least one file to be uploaded to the specified path to consider the session complete.
google_cloud_conn_id=: references a predefined connection to Google Cloud Platform for authentication and access.
task_id=: assigns a unique identifier to the sensor within the DAG.
mode=: specifies that the sensor will actively check for the file’s completion at the defined intervals.
BigQueryInsertJobOperator() - Next, we tried a different operator to run our query. This task executes a SQL query against a Google BigQuery dataset, waits for the job to complete and returns a job id. The primary functionality of this operator is to initiate and monitor the execution of a BigQuery job, providing a streamlined approach to interact with Google BigQuery from within your DAG. This approach, however, did not work for our needs. We got attribute and environment related errors when running our query.
FAILED:
AttributeError: ‘str’ object has no attribute ‘get’

Figure 8
After a few unsuccessful attempts, we decided to create our own Operator. To create a custom Operator you must nest or extend the BaseOperator() class within your custom class and override two methods - the constructor and the execute methods. This allows you to create custom parameters and override the default functions which are inherited from the BaseOperator() class. All the variables that you want to instantiate need to go in the constructor method. All the code that you want to enact needs to go in the execute method.

As you can see above, we extended the BaseSensorOperator() class and defined a custom poke function. This will run our SQL query when we call it later in the DAG definition. This sensor runs a specified SQL query using ‘BigQueryHook’ and checks the result. The ‘poke’ method is overwritten to implement the custom logic for checking the BigQuery result.
Now when we define our DAG and it’s tasks, we can pass the SQL code into our custom class BigQuerySensor().
This article can also be found on our Medium.com page.
Give us a follow as we continue to share more data science tips!